GTFS to SQLite
Testing CSV to SQL import performance in Node.js
7 min read
- Git
- Node.js
- Prisma
- SQLite
- Typescript
Introduction
Importing CSV files is a commonly encountered database operation. This project was an exploration of performance impacts I encountered while writing a node script to automate the import of General Transit Feed Specification GTFS CSV files (often 13 million plus lines) into a SQLite database.
Some of the CVS files in this dataset can be quite large so using Node.js streams was necessary. I tested import parsing performance of Node.js stream events using two popular CSV parsing libraries: csv-parse for Node.js, and PapaParse. With PapaParse, I also tested code using pipeline with the async iterator for await (const line of lines){ //do something with line...}.
I also explored the performance issues caused by frequent logging during long running operations, a few commonly recommended SQL PRAGMA settings, and the advantages of larger batch sizes for database inserts.
I used the code, and lessons learned from this project to keep the vehicle schedule database used by this project, live here in sync with Transport for Ireland (TFI)‘s public transport schedule. This was done using a Github workflow triggered nightly, and by push events to the repo’s main branch.
Testing CSV import performance
csv-parse
CSV Parse for Node.js has excellent documentation and setting up a working stream was as simple as following the example here.
return new Promise((resolve, reject) => {
csvParser.on('readable', async () => {
let record;
while ((record = csvParser.read())) {
totalLineCount++;
formattedLines.push(formatLine(record));
if (formattedLines.length >= BATCH_SIZE / MAX_TABLE_HEADER_COUNT) {
process.stdout.write('\r');
process.stdout.write(`Processing total records: ${totalLineCount}`);
await insertLines(formattedLines, fileName);
formattedLines = [];
}
}
});
csvParser.on('error', (err) => {
console.error(err.message);
reject(err);
});
csvParser.on('end', async () => {
await insertLines(formattedLines, fileName);
process.stdout.write('\r');
consola.success(`Processed ${totalLineCount} records from ${fileName}${extension}`);
resolve(record);
});
createReadStream(filePath, 'utf-8').pipe(csvParser);
});Lines are formatted during each event and pushed to an array for batch database insertion. I also tested the built in cast option for casting data types but this proved more than twice as slow (13.56 seconds) compared to performing this type conversion as part of the formatLine(record) function call (5.56 seconds) that I needed to do regardless.
PapaParse
PapaParse also supports file streams and documents setup options but does not provide clear code examples compared to csv-parse. Current version 5.4.0 of PapaParse also proved broken for stream inputs when using the header option needed to return parsed lines as an object and has been so for some time. Rolling back to version 5.3.0 proved successful.
PapaParse link-to-file performed around 50% faster compared to csv-parse when processing 13M records. (65 seconds vs. 117 seconds when skipping database insertion).
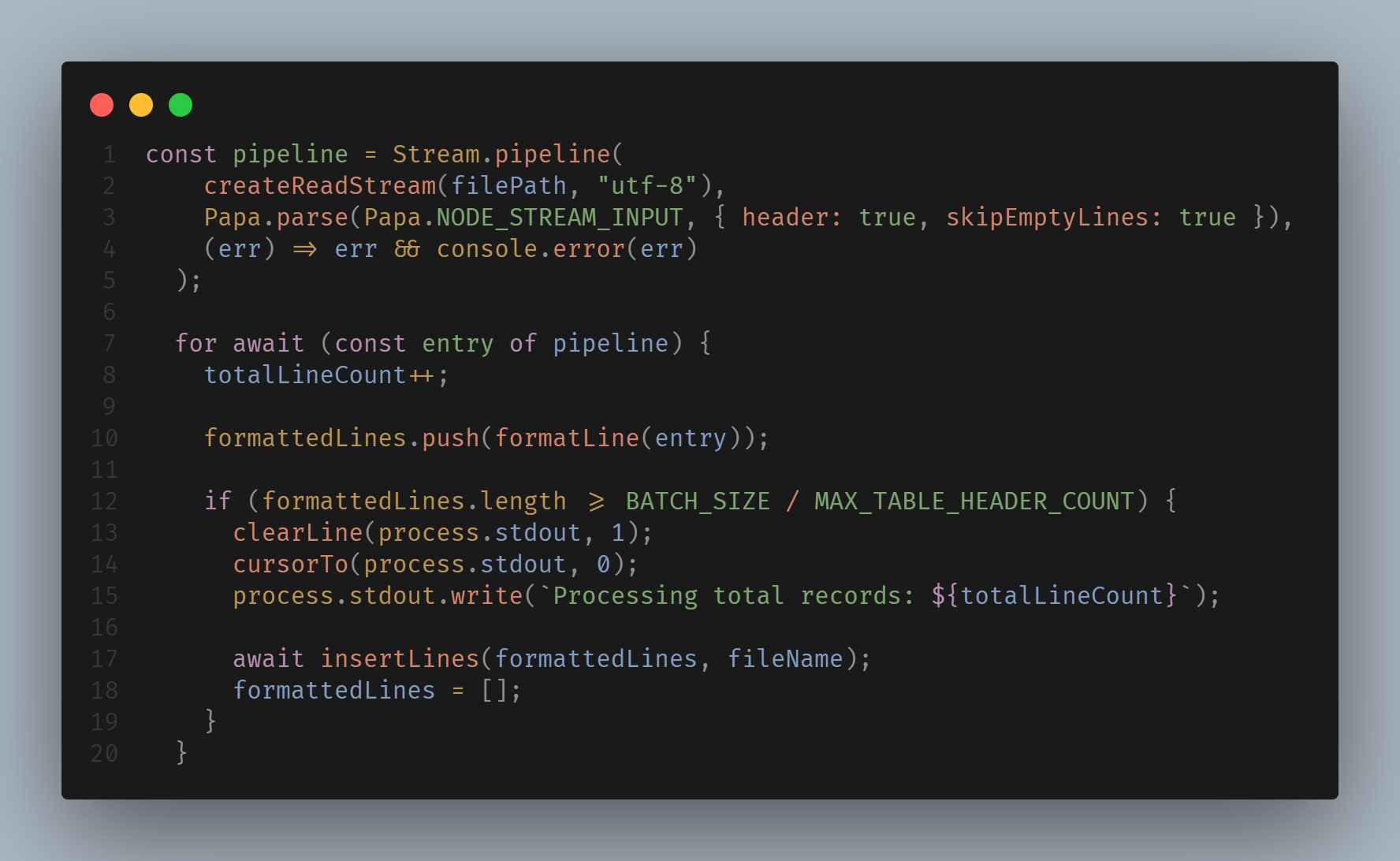
Pipeline and for await
Pipeline with a for await loop simplifies error handling and code complexity. I had high hopes for the below snippet:
let totalLineCount = 0;
let formattedLines: (string | number | null)[][] = [];
const pipeline = Stream.pipeline(
createReadStream(filePath, 'utf-8'),
Papa.parse(Papa.NODE_STREAM_INPUT, { header: true, skipEmptyLines: true }),
(err) => err && console.error(err),
);
for await (const entry of pipeline) {
totalLineCount++;
formattedLines.push(formatLine(entry));
if (formattedLines.length >= BATCH_SIZE / MAX_TABLE_HEADER_COUNT) {
clearLine(process.stdout, 1);
cursorTo(process.stdout, 0);
process.stdout.write(`Processing total records: ${totalLineCount}`);
await insertLines(formattedLines, fileName);
formattedLines = [];
}
}While the above code was simple to write compared to event based streams, it was not up to the task. PapaParse code_here took 467 seconds to complete the operation compared to just 65 seconds when using stream events.
And this was while just reading and discarding the data! It doesn’t include the actual database inserts.
This article by Dan Vanderkam here covers the problem in more detail. The short version is that creating and resolving a promise for each line entry causes significant overhead. And, while performance in node has both improved and is still actively being worked on, it has not improved enough to use for this project.
Logging and SQL
Logging surprises
Visible feedback is important for long running tasks to show that something hasn’t gotten stuck. Logging with console.log etc. unfortunately has its own performance impact. Don’t, as I did on the first iteration of this project, take the naive approach of logging every event if you are parsing 13 million records…Lets just say I was very happy when I fixed that error.
How much performance impact can it have? PapaParse takes just 54 seconds to parse 13M records when only logging the completion of each csv file (this dataset has 8 files, 6 small, two 300 KB+, depending on the week). Batching these log events to near SQLite’s transaction variable limit (which is required when actually inserting into a database) increased parse time to 65 seconds. Logging every event took 2446 seconds…40 minutes of my time wasted for science. Not counting my time wasted before I found this bug. This does not include database insert or doing anything at all with the parsed data. 39 minutes is spent just logging lines to the console.
SQLite Pragma
Performance of common PRAGMA settings on 330k records
PRAGMA statements are specific to SQLite and modify library’s operation. They are often mentioned in discussions of SQLite performance. A quick google reveals five frequently recommended PRAGMA settings worth exploring: JOURNAL_MODE=OFF, SYNCHRONOUS=OFF, CACHE_SIZE, LOCKING_MODE=EXCLUSIVE, and TEMP_STORE=MEMORY.
JOURNAL_MODE and SYNCHRONOUS are the ones I was most interested in. JOURNAL_MODE effects the rollback journal that helps prevent database corruption if the application crashes during a database transaction. SYNCHRONOUS normally helps prevent database corruption from operating system crashes or in the event of total power loss.
In a production database storing user data, disabling JOURNAL_MODE and SYNCHRONOUS is probably not a good idea. When building a read only database, however, they are perfect. In the case of application or system crash, the build script will just restart.
I tested these above five PRAGMA settings individually with a truncated 330k record dataset. Disabling journal mode and synchronous were the only PRAGMA with noticeable impacts for this small operation.
| Parser | Pragma | average seconds 3 runs |
|---|---|---|
| PapaParse | no pragma | 5.66 |
| PapaParse | journal_mode = OFF | 4.947 |
| PapaParse | synchronous = OFF | 4.80 |
| PapaParse | cache_size = 1000000 | 5.605 |
| PapaParse | locking_mode = EXCLUSIVE | 5.46 |
| PapaParse | temp_store = MEMORY | 5.596 |
Incrementally adding PRAGMA settings until all are enabled
Before changing any default PRAGMA SETTINGS, papaParse took almost 21 minutes to import the full dataset of 13 million records. This was obviously not production ready. Disabling JOURNAL_MODE and SYNCHRONOUS offered noticeably performance benefits on 330k records but how would these modes impact performance against the full dataset? The next step was to incrementally include the common recommending PRAGMA settings to find out.
| Parser | Pragma | total seconds |
|---|---|---|
| PapaParse | no pragma | 1255.21 |
| PapaParse | journal_mode = OFF | 761.96 |
| PapaParse | synchronous = OFF | 405.08 |
| PapaParse | cache_size = 1000000 | 317.15 |
| PapaParse | locking_mode = EXCLUSIVE | 318.75 |
| PapaParse | temp_store = MEMORY | 318.26 |
JOURNAL_MODE, SYNCHRONOUS, and CACHE_SIZE were the winners here. Now I was finally seeing more reasonable run times. LOCKING_MODE and TEMP_STORE had no noticeable effect. At least in this use case, they are probably not worth bothering with. Maybe for read, update, or delete operations they have a noticeable impact.
Impact of Cache size on memory usage
Cache size effects how many database pages can be held in memory for an open database. Proper settings are dependent on your hardware or service. I did not play around with these settings in any great detail more than the obvious works on my system and also, importantly, works on my deployment. It saved around 80 seconds at the expense of a noticeable increase in memory usage. I’ll leave any further explanation of the setting details to the official docs.
| Parser | Pragma | Max memory | total seconds |
|---|---|---|---|
| PapaParse | cache_size not set | 1368.37 MB | 406.53 |
| PapaParse | cache_size = 1000000 | 2215.37 MB | 318.21 |
| PapaParse | cache_size = -1000000 | 1999.53 MB | 325.75 |
Batching SQLite inserts
The last impact I explored was batching database inserts. The TLDR here is that as long as you are under the SQLite max variable limit (32766 for SQLite versions after 3.32.0), larger batches are better.
Partial dataset 330k records
Insert comparison for normalizing batches of 9_000 records.
| Parser | Notes | Average runtime |
|---|---|---|
| PapaParse | events | 4.70 |
| PapaParse | pipeline & for await(…) | 7.24 |
| csv-parse | events | 5.56 |
| csv-parse | w/cast values function | 13.74 |
| csv-parse | node-gtfs implementation | 5.10 |
Complete dataset 13M records
| Parser | Notes | Average Runtime | in Minutes |
|---|---|---|---|
| PapaParse | w/ SQL PRAGMA | 300 | 5.05 |
| node-gtfs | Batch limit: 800 | 1087 | 18.11 |
| node-gtfs | Batch limit: 8_000 | 510 | 8.65 |
| node-gtfs | Batch limit: 20_000 | 397 | 6.61 |
| node-gtfs | Batch limit: 30_000 | 406.5 | 6.78 |
Complete dataset 13M records, skip database insert
| Parser | Notes | Runtime seconds |
|---|---|---|
| PapaParse | 65 | |
| csv-parse | 118 | |
| PapaParse | pipeline & for await(…) | 467 😢 |
| PapaParse | log all 13M events | 2446 - 40.76 minutes 😵 |
| node-gtfs | Batch limit: 800 | 213 |
| node-gtfs | Batch limit: 8_000 | 171 |
| node-gtfs | Batch limit: 20_000 | 162 |
Useful resources
- node-gtfs - Import and Export GTFS transit data into SQLite. Query or change routes, stops, times, fares and more.
- Transport operator schedule data
- NTA GTFS realtime api
- General transit feed specifications